yuu_nkjm blog
メニュー
検索
タグクラウド
- .htaccess
- Apache
- CMS
- Cisco
- DF
- Eclipse
- Firefox
- FreeSoft
- Java
- KVM
- LVM
- Linux
- MABS
- MSOffice
- MySQL
- Network
- PHP
- Postfix
- Pukiwiki
- R言語
- SVN
- Samba
- TeX
- Troubleshooting
- VirtualBox
- Webアプリ
- Windows
- Windows 7 (64bit)
- X11
- Xming
- backup
- bash
- bat
- coLinux
- command
- find
- grep
- misc
- openSUSE
- ssh
- syslog
- tDiary
- サーバまとめ
- 出張
- 和食
- 岩波書店
- 物語
- 研究
- 読書ログ
- 食べログ
全カテゴリ
全カテゴリ | .htaccess |
32bit-64bit |
AWS |
Acrobat |
Android |
Ant |
Apache |
Aptana |
B4課題 |
BenchMark |
Buffalo |
C/C++ |
CMS |
CSS |
CakePHP |
Chef |
Chrome |
Cisco |
CitySim |
DF |
DNS |
DTD |
EaseUS |
Eclipse |
Excel |
FTP |
Fedora 6-7 |
Firefox |
FreeSoft |
GDocs |
Ghostscript |
GitHub |
Google |
Gparted |
H2 |
HTML5 |
HW |
Hatena |
IntelliJ |
JMeter |
JSON-RPC |
JVM |
Java |
Java8 |
JavaScript |
Jenkins |
KVM |
Kawa |
Kindle |
Knoppix |
LVM |
Langrid |
Language |
Links |
Linkstation |
Linux |
LinuxDesktop |
LinuxLanguage |
Linuxお引っ越し |
Lucene |
MABS |
MATSim |
MSOffice |
Maven |
Monit |
MySQL |
NLP |
Network |
Nexus |
OSM |
PDF |
PDIC |
PHP |
POSIX |
PhpStorm |
Polycom |
Postfix |
Postgress |
PowerDirector |
Profiler |
Programming |
PuTTY |
Pukiwiki |
Python |
RDBMS |
RHEL |
Research |
Ruby |
R言語 |
SQL |
SQLite |
SSD |
SSL |
SUMO |
SVN |
Samba |
ScanSnap |
Scheme |
Scrap |
Script |
Servlet |
Shell |
Skype |
SoftwareDevelopment |
Spring |
Stone |
SugarSync |
Swing |
TFTP |
TeX |
Tomcat |
Troubleshooting |
Tweet |
UPS |
UWSC |
Vagrant |
VirtualBox |
WebDav |
WebSite |
Webアプリ |
Wikipedia |
Windows |
Windows 7 (64bit) |
Windows 8 |
Windows10 |
WindowsServer2003 |
Windowsお引っ越し |
Windowsまとめ |
WishList |
WordPress |
X10 |
X11 |
XAMPP |
XML |
Xming |
YOLP |
YaST |
apply |
arp |
awk |
backup |
bash |
bat |
bcdedit |
bind |
blog |
book |
boot |
bootrec |
bundler |
coLinux |
command |
cron |
curl |
dd |
diskpart |
dropbox |
dviout |
fail2ban |
find |
fml |
gdb |
gem |
git |
grep |
grub |
https |
iPad/iPodTouch/iPhone |
iptables |
jQuery |
jad |
joomla |
letsencrypt |
locate |
log4j |
logrotate |
logwatch |
lsof |
man |
misc |
mod_rewrite |
mount |
netstat |
nkf |
nmb |
ntldr |
nyaos |
openSUSE |
perl |
pgrep |
php |
ping |
pkill |
python |
route |
rsync |
sakura |
sed |
squid |
ssh |
sudo |
svn |
syslog |
tDiary |
tail |
taskkill |
tcpdump |
telnet |
update-alternatives |
w2box |
wget |
wmic |
xargs |
xdebug |
zypper |
お友達 |
お名前.com VPS (KVM) |
お引っ越し |
サーバまとめ |
ネタ |
フレンチ |
プロファイラ |
リフレクション |
リンク |
レビュー |
人文 |
例外 |
先斗町 |
出張 |
助成 |
動画編集 |
吉田さかみち |
和食 |
岩波書店 |
技術書 |
料理 |
新潮社 |
物語 |
生活 |
百万遍 |
研究 |
読書ログ |
講談社 |
電子書籍 |
食べログ
カレンダー
更新情報

2014-07-01(Tue) [長年日記] 編集
[H2][SQL][RDBMS] H2 Databaseいろいろ
なぜh2 データベースを使ってみたか,なぜ気に入ったか
- Javaが動けば,1MBぐらいのjarを落としてくるだけで動く.インストールが簡単,アプリに組み込みやすそう.sqliteと同じ様な手軽なイメージ.
- Javaで書かれているのでJavaとの親和性が高そう.ストアドプロシージャがないみたいだが,ややこしいことやるならJavaで書けば良さそう.
- WebUIがついてくるのが意外と便利.
- インメモリモードがあるのがなんか面白そう.
- dbのデータファイルがシンプルなので,バックアップが簡単そう.
h2の起動
こんな感じで起動.-baseDirというオプションもある.*.dbや.h2.server.propertiesの出来る位置がイマイチ分からん.
@start javaw -cp "h2-1.4.179.jar;postgresql-8.3-607.jdbc4.jar;%H2DRIVERS%;%CLASSPATH%" org.h2.tools.Console -webAllowOthers -tcpAllowOthers -pgAllowOthers %* @if errorlevel 1 pause
便利な関数
これで読める.
SELECT * FROM CSVREAD('test.csv');
属性名の指定(無指定の時は1行目が属性名として用いられる),文字コード,区切り文字,引用符文字(カンマからカンマまでを囲む文字),エスケープ文字を指定しても読み込める.特に指定したく無いときはnullを渡せば良い.
CSVREAD('game_logs.txt','ID,SESSION_ID,MESSAGE, ROUND_NUM,','utf-8',',','"','\');
Excelからcsv作った時の定番はこの変かな.char(9)はタブ区切りということ.
SELECT * FROM CSVREAD('HumanSubjects.csv', null, null, char(9));
INSERT INTO TESTTABLE SELECT * FROM CSVREAD('HumanSubjects.csv', null, null, char(9));
SQL
- UNIONで和集合が取れる.同じクエリを複数のテーブルに投げて結果をまとめるのに便利.
- 順番を並び替えたいならUNIONしたあとにORDER BYすればOK.H2に限らないけど,ORDER BY A, Bとすれば,複数の属性を使ってソート出来る.
CREATE VIEW FP AS SELECT * FROM (SELECT WASEDA01_DECISION_LOGS.CREATE_AT, SESSION_ID, WASEDA01_USERS.USER_ID, ROUND, VALUE FROM WASEDA01_DECISION_LOGS JOIN WASEDA01_USERS ON WASEDA01_DECISION_LOGS.USER_ID=WASEDA01_USERS.ID WHERE NAME='proposition') UNION (SELECT WASEDA02_DECISION_LOGS.CREATE_AT, SESSION_ID, WASEDA02_USERS.USER_ID, ROUND, VALUE FROM WASEDA02_DECISION_LOGS JOIN WASEDA02_USERS ON WASEDA02_DECISION_LOGS.USER_ID=WASEDA02_USERS.ID WHERE NAME='proposition') UNION (SELECT WASEDA03_DECISION_LOGS.CREATE_AT, SESSION_ID, WASEDA03_USERS.USER_ID, ROUND, VALUE FROM WASEDA03_DECISION_LOGS JOIN WASEDA03_USERS ON WASEDA03_DECISION_LOGS.USER_ID=WASEDA03_USERS.ID WHERE NAME='proposition') ORDER BY SESSION_ID, ROUND;
- CASEWHENという関数が使える.一つ目の引数が条件(述語),二つ目の引数が条件が真の時の式,三つ目の引数は条件が偽の時の式.
- CAST関数が使える.CAST(val AS type)という書式で使う.
DROP VIEW FP_SP; CREATE VIEW FP_SP AS SELECT FP.CREATE_AT, FP.SESSION_ID, FP.ROUND, FP.USER_ID AS FP, CAST(FP.VALUE AS INT) AS PROPOSITION, CASEWHEN(SP.VALUE='no', 0, 100000-FP.VALUE * CASEWHEN(SP.VALUE='no', 0, 1)) AS PROFIT_OF_FP, SP.USER_ID AS SP, SP.VALUE AS YES_OR_NO, FP.VALUE * CASEWHEN(SP.VALUE='no', 0, 1) AS PROFIT_OF_SP, CASEWHEN(SP.SESSION_ID<='proc-20140519-165442-428', '非匿名', '匿名') AS ANONYMITY FROM FP JOIN SP ON (FP.SESSION_ID=SP.SESSION_ID AND FP.ROUND=SP.ROUND)
- CASEWHEN関数の結果を他の関数の引数として渡すことも出来る.
SELECT ANONYMITY, AVG(PROPOSITION), AVG(PROFIT_OF_FP), AVG(PROFIT_OF_SP), SUM(CASEWHEN(YES_OR_NO='no', 0, 1)) AS SUM_OF_YES FROM FP_SP GROUP BY ANONYMITY;
- SELECT * From (SELECT * FROM TABLE_A WHERE ATTR=1) JOIN TABLE_B ON ....のようにSELECTの中でSELECTができる.
他の便利そうな機能
ORマッパー
ORマッパーにはpersistを使っている.特に不満はない.でも,apaheのプロジェクトの奴の方が寿命が長いのかなぁ.Apache Commons DbUtils - nodchipの日記.「薄い」JavaのO/Rマッパーの紹介 - DbUtils、Persist、Butterfly Persistence - public static void mainあたりを参照.
参考にしたページ
[ツッコミを入れる]
2014-07-24(Thu) [長年日記] 編集
[MySQL][SQL][RDBMS] プロファイリングとインデックスの作成
MySQLの負荷が高い · Issue #5 · MAGCruise/MAGCruiseWebUIの事例を元に書く.
時間のかかっているクエリを探すには,slow query logを使う. 漢(オトコ)のコンピュータ道: MySQL 5.1のスロークエリログ
漢(オトコ)のコンピュータ道: プロファイリングで快適MySQLチューニング生活.プロファイリング.
[ツッコミを入れる]
2014-07-25(Fri) [長年日記] 編集
[JMeter][プロファイラ] JMeterを使ってログインが必要なサイトにアクセスする,JSON形式のデータをPOSTする
apache-jmeter-2.11の画面で説明する.↓スクリーンショットはsetUp Thread Groupになっているけど,サンプラが直列実行されないっぽい.通常のスレッドグループだと直列実行になるのかな.
リクエストの作成
- どれだけアクセスするか決める.
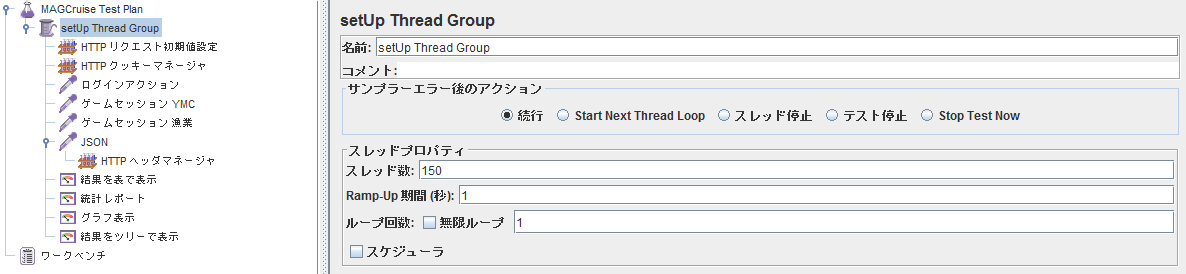
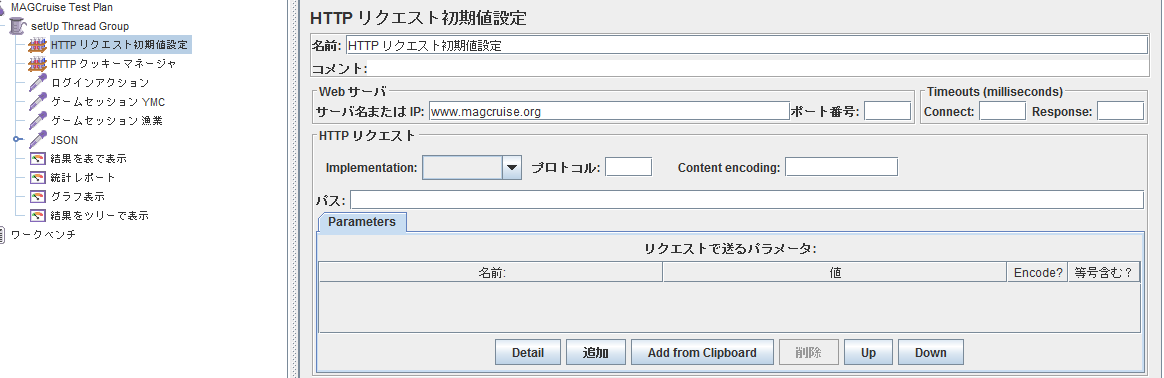
- HTTPリクエストの共通部分を設定.
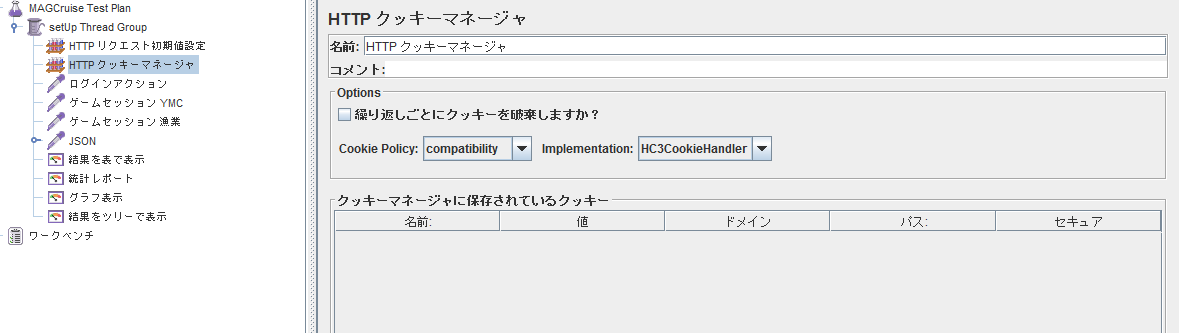
- ログイン情報を残せるようにクッキーマネージャーを設定.
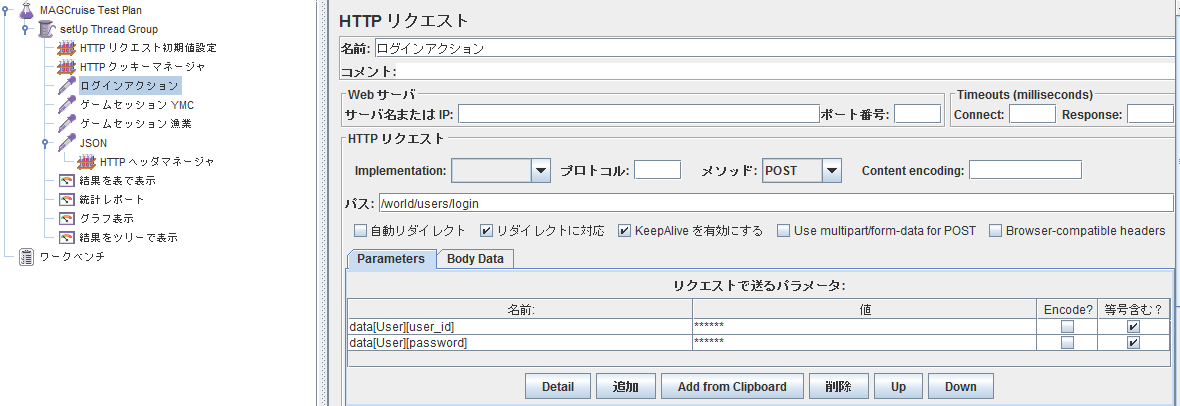
- ログインをする.ログインフォームのnameなどを見て,リクエストで送るパラメータの名前と値を決める.メソッドがGETなのかPOSTなのかを気をつける.
- HTTPリクエストを使って,通常のGETアクセスをする.
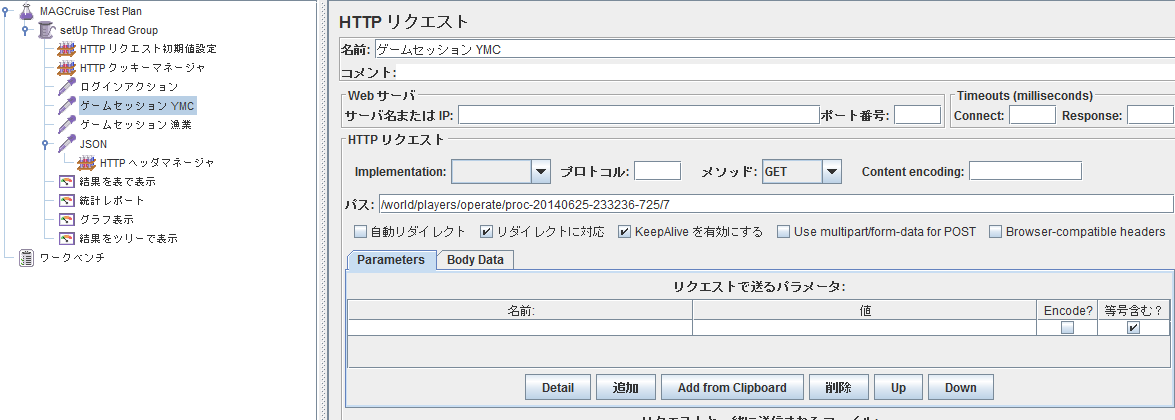
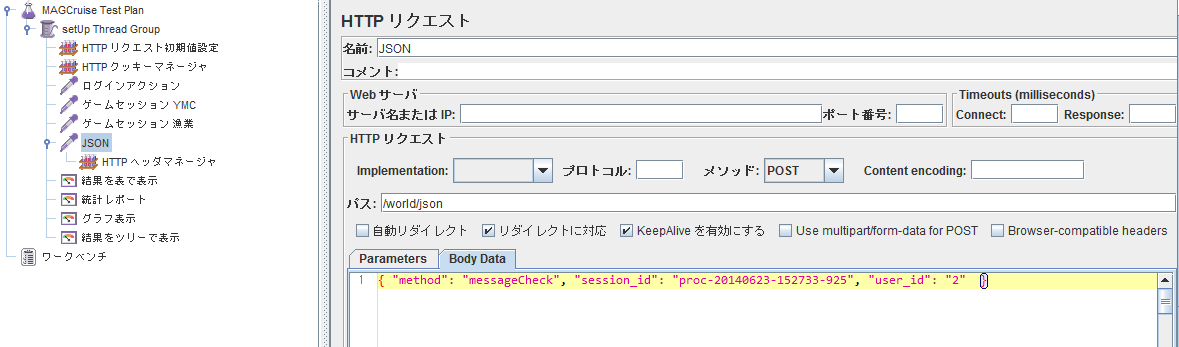
- HTTPリクエストを使って,JSONをポストする.メソッドをPOSTにする.Body Dataに送りたいJSONを入力する.
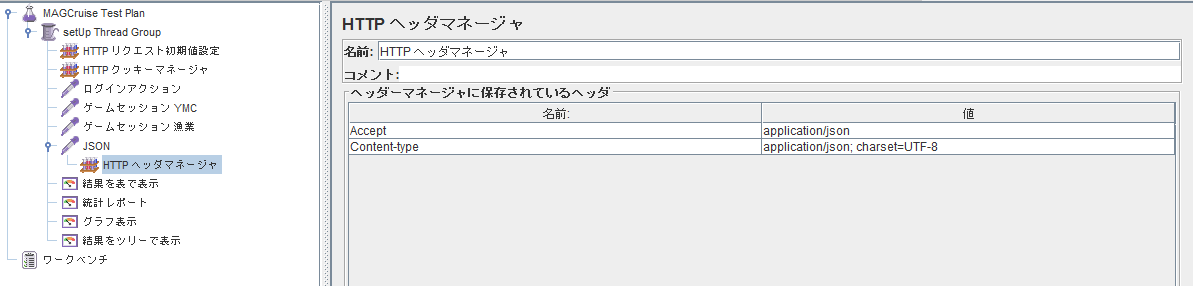
- JSONの送受信にはHTTPヘッダの指定が必要である.この指定はJSONのHTTPリクエストだけにかかるようにする.
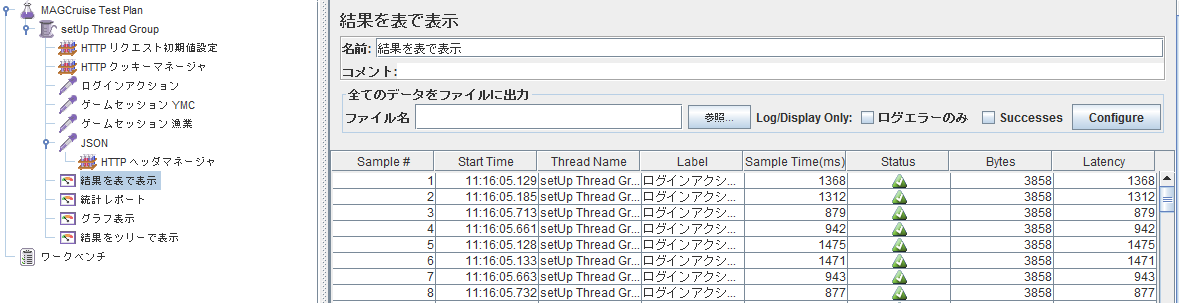
集計結果やレスポンスの閲覧
再生ボタン(右矢印ボタン)を押すとリクエストが実行される.
- 結果を表で表示:リクエストが失敗したら赤三角になる.
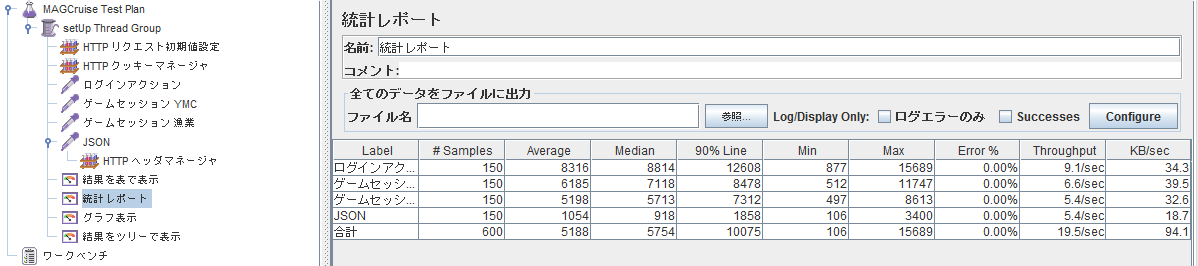
- 統計レポート:最良値,最悪値,スループットなどが見られる.
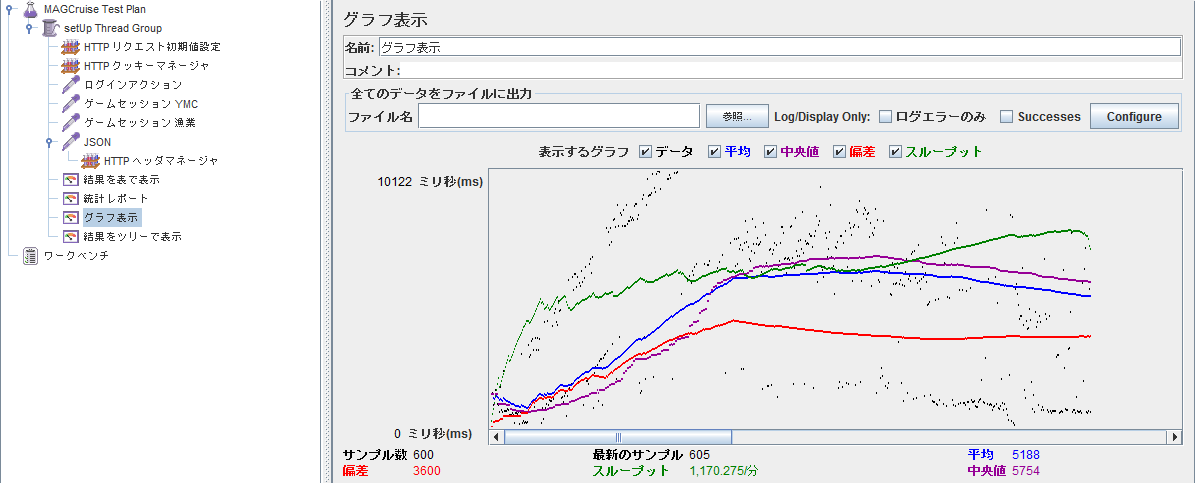
- グラフ表示:リクエスト結果のグラフ表示.
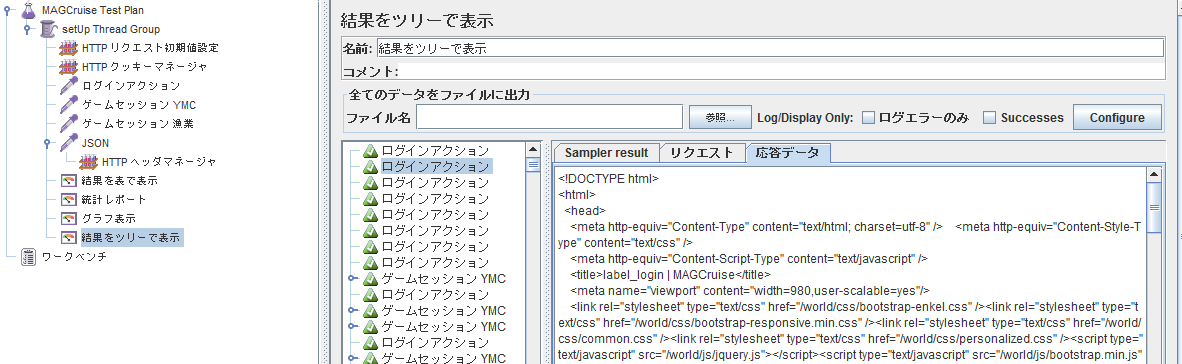
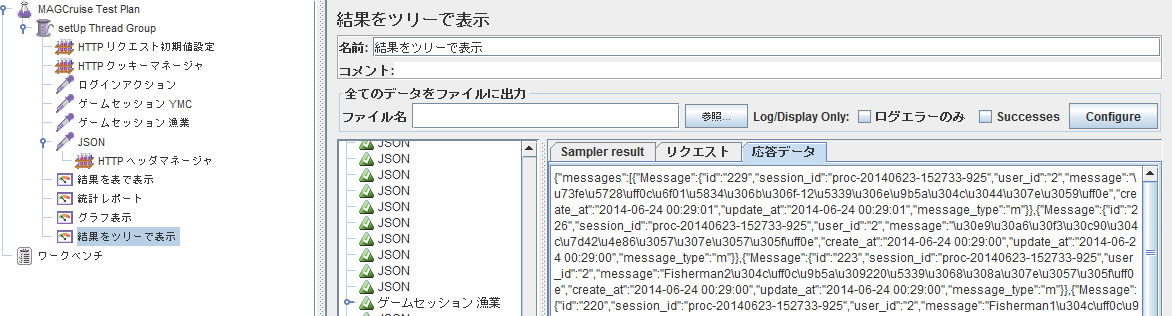
- 結果をツリーで表示:レスポンスが見られる.レスポンスを見ることで正しくログインが出来ているか,正しいJSONリクエストが出来ているかなどの確認ができる.
参考ページ
[ツッコミを入れる]